
Hyperledger Fabric Meets Kubernetes
Summary
Looks like our project is globally pioneering the process of running Hyperledger Fabric in Kubernetes and getting close to a production-ready setup step by step.
I’m also very happy and proud to announce that, this work is now open source and hopefully will fill a large gap in the Hyperledger Fabric community.
https://github.com/APGGroeiFabriek/PIVT
Special thanks to APG for allowing opening the source code :)
Contents
- What is This?
- Motivation
- Difficulty
- Existing Work
- Network Architecture
- PIVT Way
- How it Works?
- Backup/Restore
- Accenture Architecture Concerns
- Future (Dream) Work
- Conclusion
What is this?
These are a couple of Helm charts to:
- Configure and launch the whole Hyperledger Fabric network, either:
- A simple one, one peer per organization and Solo orderer
- Or scaled-up one, multiple peers per organization and Kafka orderer
- Raft orderer is work in progress
- Populate the network:
- Create the channels, join peers to channels, update channels for anchor peers
- Install/Instantiate all chaincodes, or some of them, or upgrade them to newer version
- Backup and restore the state of whole network
Motivation
Hyperledger Fabric provides some samples to launch and populate the network as plain Docker containers. We were also using this setup before moving to Kubernetes.
This is a good starting point for newcomers but obviously not a production ready setup:
- No management layer on top of it
- If a container dies, nothing will restart it
- If virtual machine crashes!?
- No monitoring, alerts, etc.
- Not scalable, no easy way of spreading containers among VM’s
- …
In addition, it is difficult to configure when network structure changes
- Lots of boilerplate Docker Compose files
- Pages of Bash scripts are difficult to maintain and use in the CD pipelines
- Maintaining port numbers in CD pipelines is also a pain
Since we are already deploying everything else to Kubernetes, moving HL Fabric to Kubernetes was the obvious choice
Difficulty
Launching the network
- Each component in the HL Fabric network needs specific MSP (Membership Service Provider) and TLS certificates
- In plain Docker setup, this is relatively easy as all containers are running in the same VM, relevant directories are mounted to containers
- This is not an option in Kubernetes. By default, we don’t have access to VM’s and even if we do, it’s not a good practice to copy every certificate to every VM
Populating the network
- Channels: creating channels and joining peers to relevant channels with Bash scripts is not good enough
- Chaincode: similarly installing/instantiating/upgrading chaincodes on relevant peers with Bash scripts is not good enough
- These scripts can be improved with some looping etc. but still…
Existing Work
Existing Work - Launching The Network
AID:Tech Helm Charts
- These are the Helm charts demonstrated in the Hyperledger forum last year
- Not by HL guys but by AID:Tech, a blockchain-oriented company based in Dublin, London and New York
- The charts are nice but not reducing complexity at all
- There are different charts for HL Fabric Orderer, Peer, CouchDB and CA
- You need to manually create Kubernetes secrets for TLS and MSP certificates etc. for each of these components
- You also need to manually deploy many copies of Peer and CouchDB for instance and configure each of them separately, which totally misses the point!
- https://hub.kubeapps.com/charts?q=hlf
- https://github.com/aidtechnology/hgf-k8s-workshop
Others
One sample provided by one of HL Fabric contributors (Alex)
- Not using Helm, just plain yaml Kubernetes manifest files
- Using a shared NFS server / volume to mount everything to all pods (not a good idea I guess)
- Everything is still should be manually configured, so not reducing complexity at all
- One nice idea is running peer and CouchDB containers in the same pod, which I borrowed, more on this later
- https://github.com/feitnomore/hyperledger-fabric-kubernetes
Also one sample by IBM
- Not using Helm, just plain yaml Kubernetes manifest files
- Everything is still should be manually configured, so not reducing complexity at all
- https://github.com/IBM/blockchain-network-on-kubernetes
Existing Work - Populating the Network
- To my knowledge, no work exists for populating the network
- In the mentioned samples, manual commands are used
- Or a script file of list of commands is used, which is basically the same
- It feels like, this part is highly overlooked, which I believe since none of the samples mentioned are meant to go to production. They were just PoCs
Network Architecture
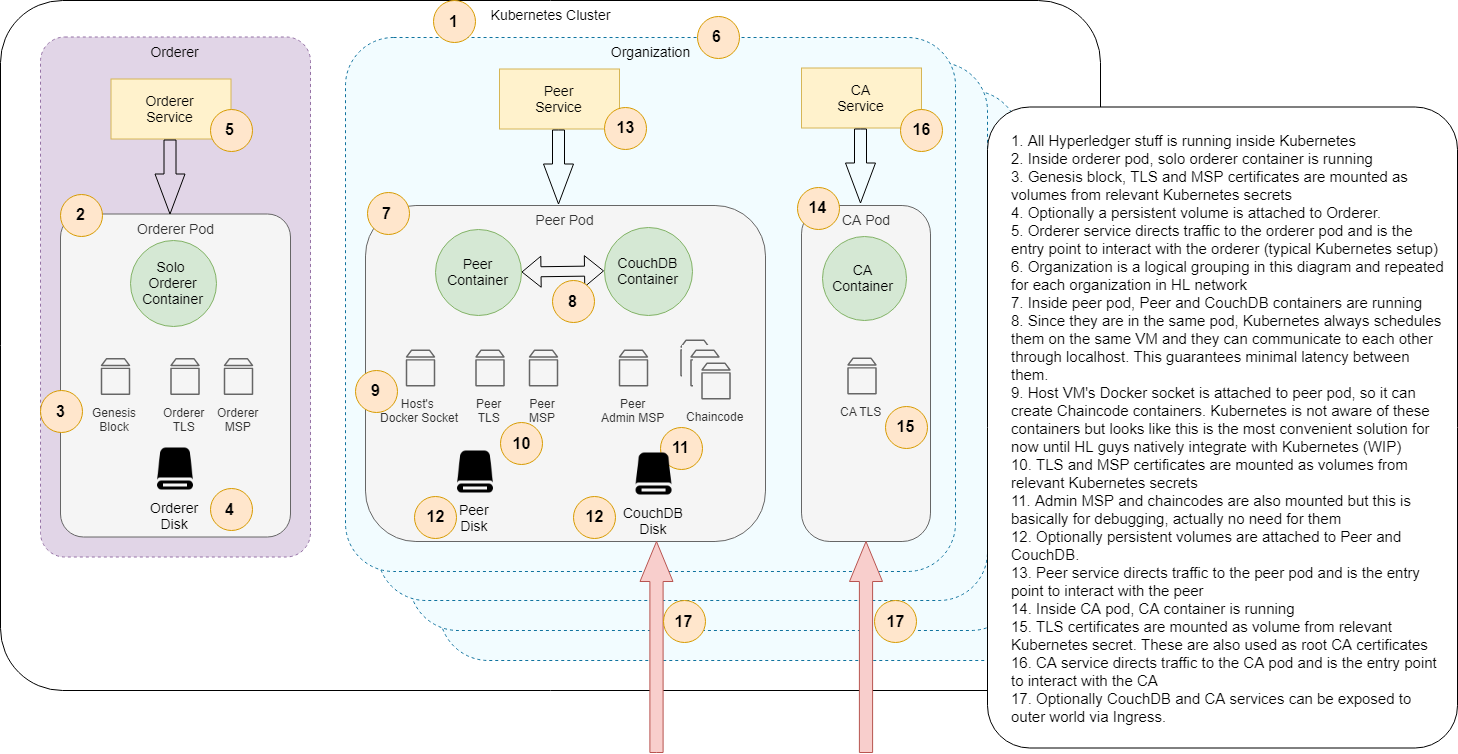
Simple Network Architecture
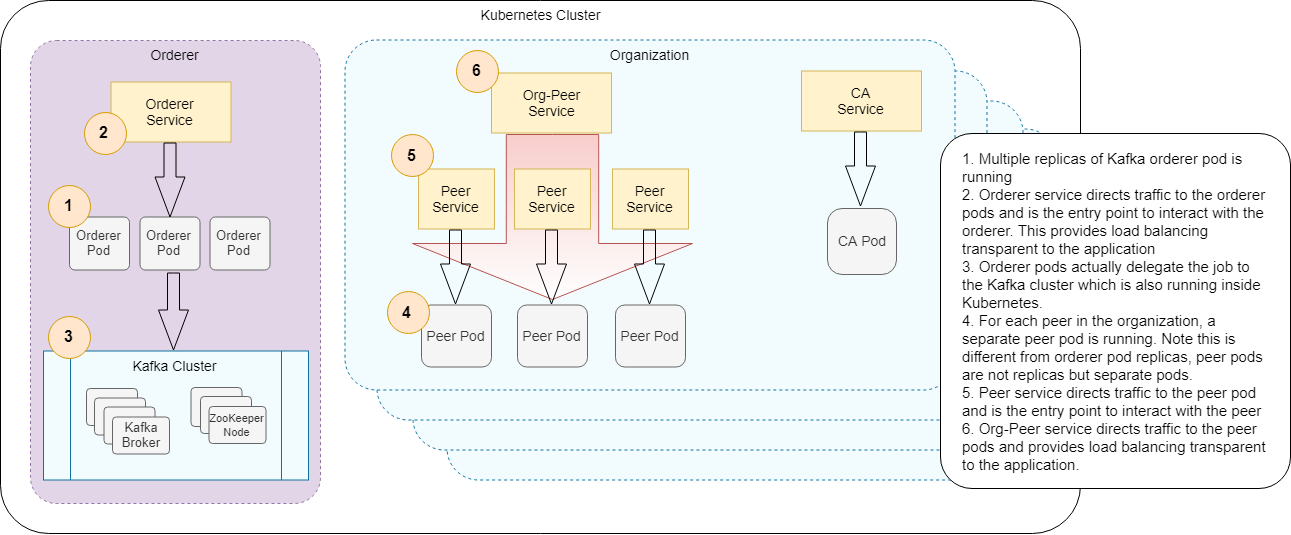
Scaled Up Network Architecture
PIVT Way
PIVT Way - Launching the Network
After creating crypto material and channel artifacts, launching the network is as simple as:
helm install -f crypto-config.yaml ./hlf-kubeThe crypto-config.yaml is actually HL Fabric’s own configuration file, so we are not maintaining multiple copies of same information
This honors OrdererOrgs, PeerOrgs and even Template.Count (peer count) in crypto-config.yaml. And creates all the mentioned secrets, pods and services, cross-configures them and launches the network in unpopulated state
Hopefully, in the future, when an actor joins or exits the network, after creating crypto material, updating the network will be as simple as:
helm upgrade -f crypto-config.yaml ./hlf-kubeNote, some command arguments are omitted for brevity.
PIVT Way - Populating the Network
After network is launched, creating the channels and joining peers to relevant channels is as simple as:
helm template -f network.yaml -f crypto-config.yaml channel-flow/ | argo submit - Installing/Instantiating chaincodes on relevant channels/peers:
helm template -f network.yaml -f crypto-config.yaml ./chaincode-flow/ | argo submit -Upgrading all chaincodes to version 2.0:
helm template -f network.yaml -f crypto-config.yaml -f chaincode-flow/values.upgrade.yaml –-set chaincode.version=2.0 ./chaincode-flow/ | argo submit -Upgrading only info chaincode to version 3.0:
helm template -f network.yaml -f crypto-config.yaml -f ./chaincode-flow/values.upgrade.yaml --set chaincode.version=3.0 --set flow.chaincode.include={info} chaincode-flow/ | argo submit -Note, some command arguments are omitted for brevity.
How it works?
How it works? - Launching the Network
We are basically leveraging Helm’s template engine capabilities to iterate over every organization and peer and create relevant cross-configured Kubernetes manifest files.
Convention over configuration makes life easier; for example, every MSP name is <orgname>MSP, apgMSP, pggmMSP, etc.
Based on this convention, it collects just the right piece of data from relevant place and mounts to the correct place in the pod
How it works? - Populating the Network
Kubernetes has a concept of a job, which is basically a pod launched to perform a certain task and then stop after completion. The Helm’s power of injecting the correct data to the correct pod makes Kubernetes jobs a good candidate to populate HL Fabric network.
Launch the pod, execute the command with correct data and credentials and stop. Commands are atomic things:
- peer channel join
- peer chaincode install
- etc.
However, there was a missing part. Kubernetes is not providing a mechanism to orchestrate the jobs (i.e., that is to run the jobs in a specific order).
While searching for an orchestrating mechanism for jobs, I found Argo.
It’s a nice Kubernetes native workflow engine capable of running tasks sequentially or in parallel and also allows hierarchical grouping of tasks. It does this by defining its own resource type Workflow, thanks to Kubernetes’ extension mechanism.
Argo also provides a retry mechanism for failed tasks (yes, occasionally these tasks temporarily fail every now and then and retrying them in Bash scripts makes the scripts more complicated). So, again by leveraging Helm’s template engine capabilities, iterating over channels, chaincodes, organizations and peers, we create a workflow and execute it through Argo.
The generated chaincode install/instantiate workflow is approximately 4,500 lines. For three peers per organization, this approaches 15,000 lines. :)
Backup Restore
Backup/Restore - Motivation
It’s correct and verified that peers restore ledger state from other peers on the same channel.
However, this is not very useful on its own since:
- They do not re-join to channels on their own
- You should manually re-join them to channels so they can start restoring data
- They do not re-install chaincodes on their own
- You should manually re-install chaincodes to them otherwise chaincode invoke calls will fail
Mounting persistent volumes to peer pods effectively handles this situation.
In case of peer crash or restart for any reason, peer will start with the exact same state it was before crash/restart and will get missing data from other peers if any.
So, infrastructure wise we are 99.999999999% (11 nines) covered in terms of durability (for Azure AKS) except the very unlikely event of complete data center breakdown (fire, flood, etc.).
But this doesn’t provide any coverage against data corruption in other means
- Peer/Orderer/Kafka messes up data somehow
- Data deleted from persistent volumes by mistake or due to some attacker
- …
In particular, this can be an issue since there is no backup/restore mechanism for persistent volumes. There is also no mechanism to return back to a point in time. Once the data is gone, it’s gone forever.
Backup/Restore Flow
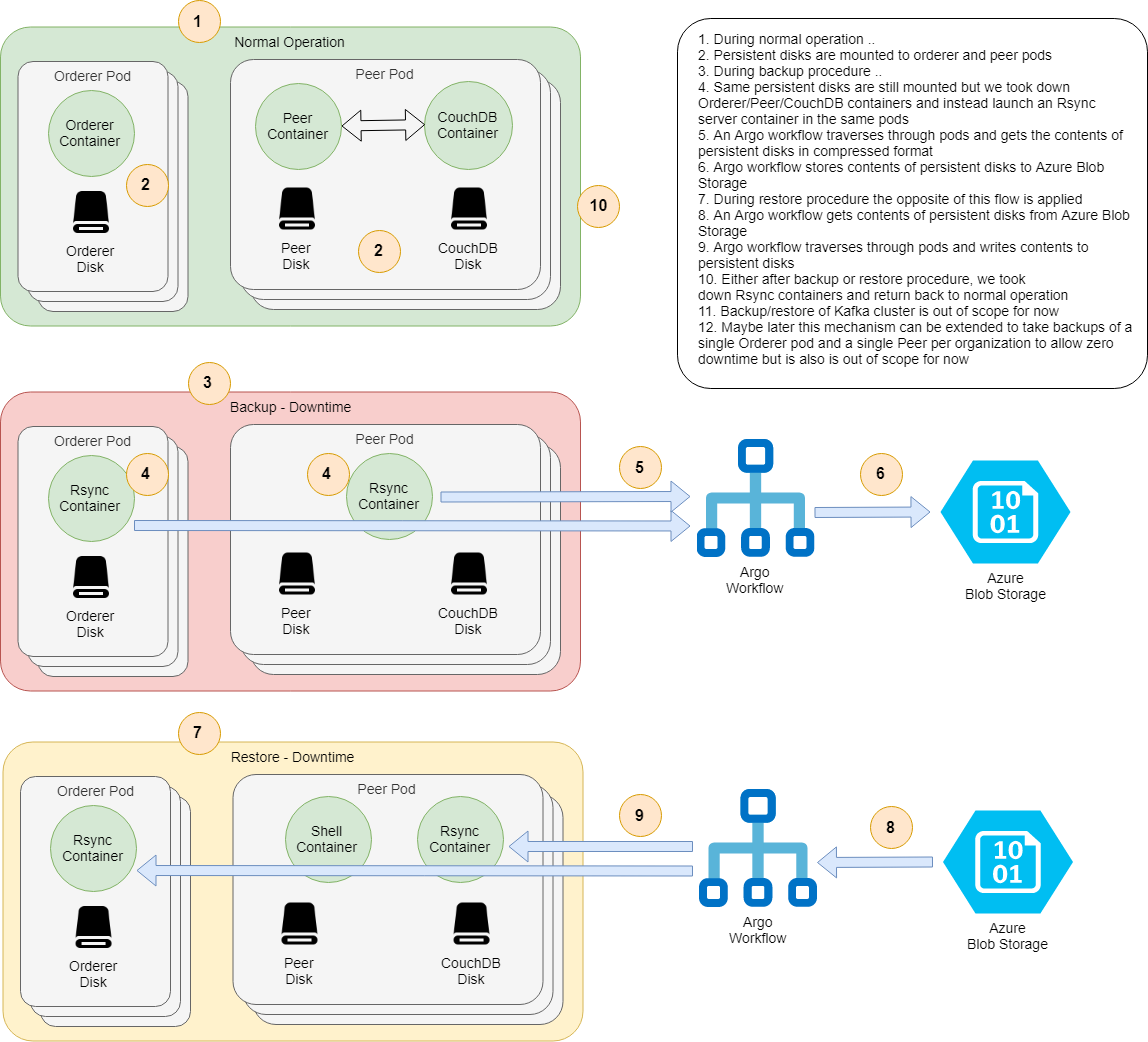
Backup:
- Start backup procedure
helm upgrade hlf-kube --set backup.enabled=true ..- Take backup:
helm template .. backup-flow/ | argo submit -- Go back to normal operation
helm upgrade hlf-kube ..Restore:
- Start restore procedure
helm upgrade hlf-kube --set restore.enabled=true ..- Restore from backup:
helm template --set backup.key=<backup key> .. restore-flow/ | argo submit -- Go back to normal operation
helm upgrade hlf-kube ..Note, some command arguments are omitted for brevity.
Accenture Architecture Concerns
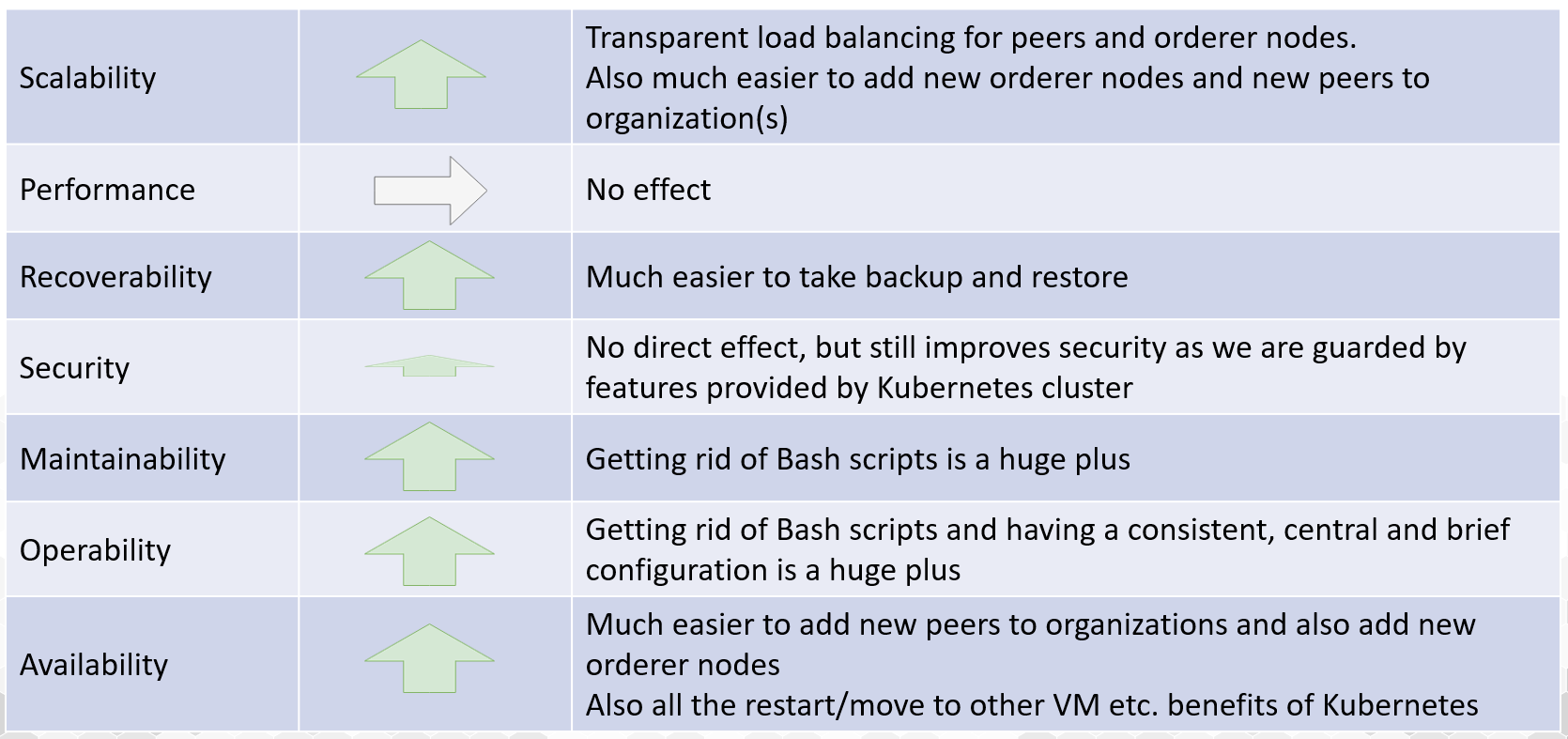
Let’s have a look what this work provides regarding Accenture’s Architecture Concerns (NFR’s)
Future (Dream) Work

Wrapping up everything in a Kubernetes Operator will be more than awesome! :) So one will provide the Operator the desired state of HL Fabric network, both the network itself and the channels, chaincodes etc., and let it reach that state if possible.
This is also consistent with Kubernetes paradigm!
Reminder:
- Kubernetes Operators are extensions to Kubernetes, they are actually custom controllers which are actively monitoring the cluster for certain resource types.
- As an example, Argo workflow controller is an Operator, which is monitoring the cluster for resources of type Workflow.
While I don’t know much about Go language, this may not be as difficult to implement if using Helm in an Operator is possible. After all, all the required bits are in place, they are just waiting to be combined!
Special thanks to Oscar Renalias for the inspiration!
Conclusion
So happy BlockChaining in Kubernetes :)
And don’t forget the first rule of BlockChain club:
“Do not use BlockChain unless absolutely necessary!”
Hakan Eryargi (r a f t)