Transparent Replication and Persistence for POJO Graphs
Java Replication Persistence Instrumentation
Transparent Replication and Persistence for POJO Graphs
Summary
This post is about a PoC (proof of concept) library called Chainvayler which provides POJOs (Plain Old Java Objects) replication and persistence capabilities almost transparently.
Chainvayler requires neither implementing special interfaces nor extending from special classes nor a backing relational database. Only some @Annotations and conforming a few rules is necessary. Chainvayler does its magic by instrumentation (injecting bytecode) of Java classes.
Either replication or persistence can be disabled independently. If replication is disabled, you will have locally persisted POJOs. If persistence is disabled, you will have your POJOs replicated over JVMs possibly spreading over multiple nodes. If both replication and persistence is disabled, well you will only have Chainvayler’s overhead ;)
I’ve found the idea really promising, so went ahead and made a PoC implementation.
Sounds too good to be true? Well, keep reading… ;)
Chainvayler can be found here.
Contents
- Motivation
- Introduction
- Bank sample
- How it works?
- Performance and Scalability
- Determinism
- Limitations
- Comparision to
- Conclusion
Motivation
Despite I appreciate the value of functional programming, I’m a fan of OOP (object oriented programming) and strongly believe it is naturally a good fit to model the world we are living in.
ORM (Object-Relational Mapping) frameworks improved a lot in the last 10 years and made it much easier to map object graphs to relational databases.
However, the still remaining fact is, objects graphs don’t naturally fit into relational databases. You need to sacrifice something and there is the overhead for sure.
I would call the data model classes used in conjunction with ORM frameworks as object oriented-ish, since they are not truly object oriented. The very main aspects of object oriented designs, inheritance and polymorphism, and even encapsulation is either impossible or is a real pain with ORM frameworks.
Wouldn’t it be great if our objects are automagically persisted and replicated? Do we really need that additional persistence layer? Do we really need that @NamedQueries and so on?
And looks like this is indeed possible…
Introduction
As mentioned, Chainvayler only requires some @Annotations and conforming a few rules.
Here is a quick sample:
@Chained
class Library {
final Map<Integer, Book> books = new HashMap<>();
int lastBookId = 1;
@Modification
void addBook(Book book) {
book.setId(lastBookId++);
books.put(book.getId(), book);
}
}
Quite a Plain Old Java Object, isn’t it? Run the Chainvayler compiler after javac and then to get a reference to a chained instance:
Library library = Chainvayler.create(Library.class);
or this variant to configure options:
Library library = Chainvayler.create(Library.class, config);
Now, add as many books as you want to your library, they will be automagically persisted and replicated to other JVMs. Kill your program any time, when you restart it, the previously added books will be in your library.
Note, the call to Chainvayler.create(..) is only required for the root of object graph. All other objects are created in regular ways, either with the new operator or via factories, builders whatever. As it is, Chainvayler is quite flexible, other objects may be other instances of root class, subclasses/superclasses of it, or instances of a completely different class hierarchy.
@Chained annotation marks the classes which will be managed by Chainvayler and @Modification annotation marks the methods in chained classes which modifies the data (class variables).
Bank sample
Chainvayler comes with a Bank sample, for both demonstration and testing purposes.
Below is the class diagram of the Bank sample:
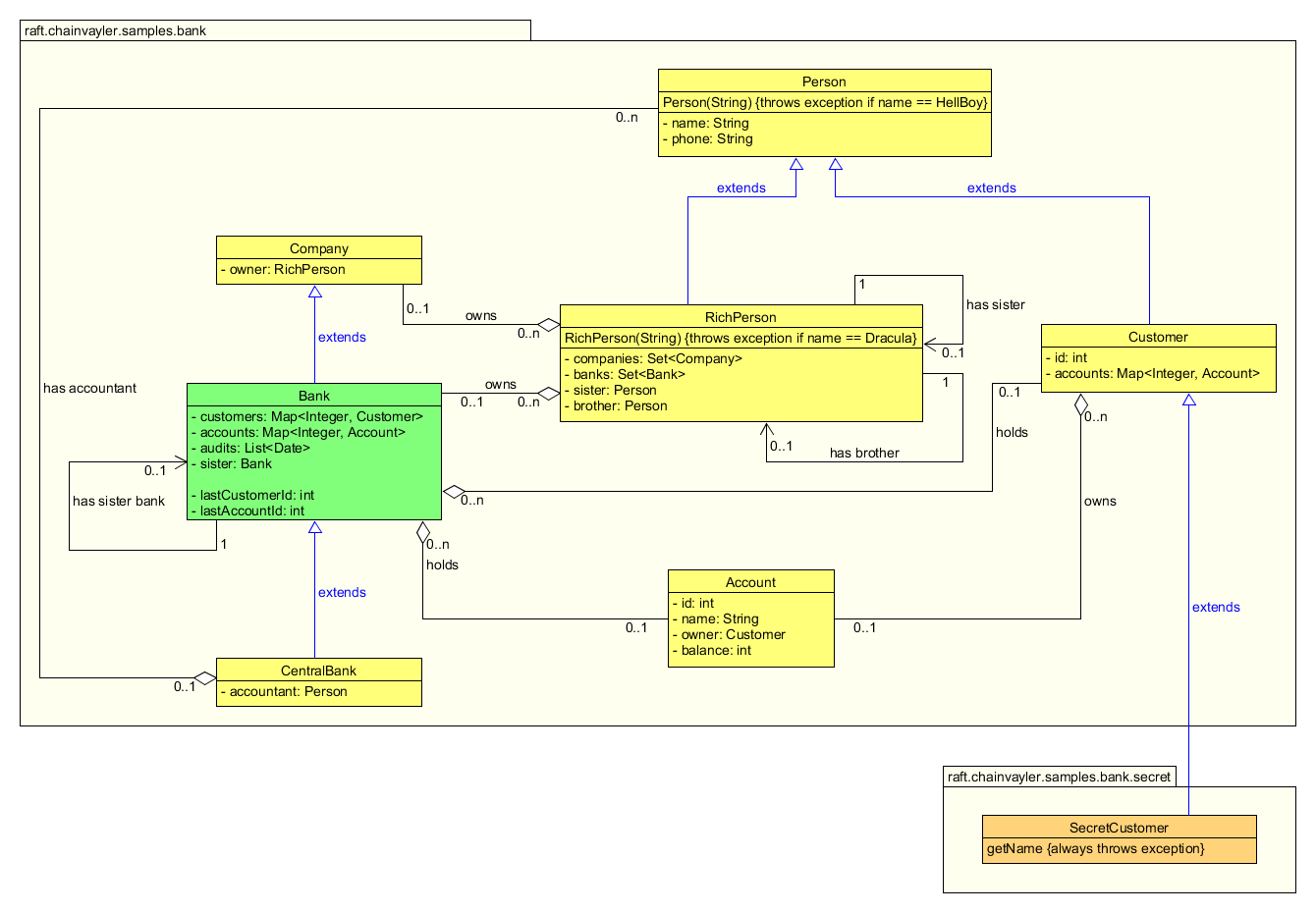
Nothing much fancy here. Apparently this is a toy diagram for a real banking application, but hopefully good enough to demonstrate Chainvayler’s capabilities.
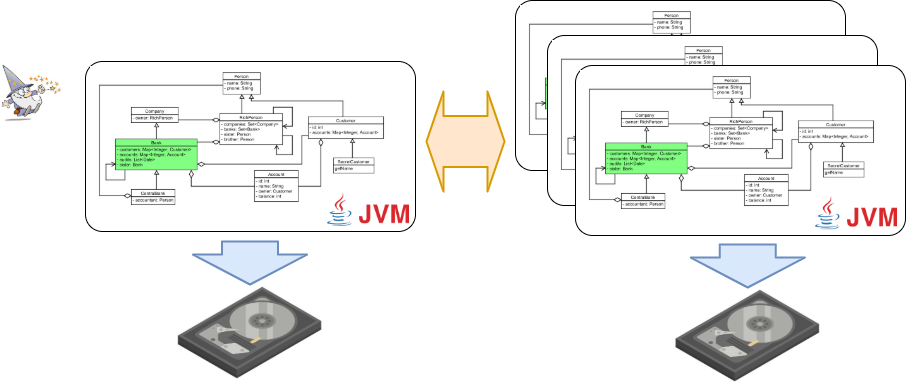
Bank class is the root class of this object graph. It’s used to get a chained instance of the object graph via Chainvayler. Every object reachable directly or indirectly from the root Bank object will be chained (persisted/replicated). Notice Bank class has super and sub classes and even has a reference to another Bank object.
For the sake of brevity, I’ve skipped the class methods in the diagram but included a few to demonstrate Chainvayler’s capabilities regarding some edge cases.
There is also an emulated Bank sample where the Chainvayler injected bytecode is manually added to demonstrate what is going on.
See the instructions in the repo for how to run the Bank sample both in Kubernetes and locally with Gradle.
How it works?
Prevayler
To explain how Chainvayler works, I need to first introduce Prevayler. It is a brilliant library to persist real POJOs. In short it says:
Encapsulate all changes to your data into Transaction classes and pass over me. I will write those transactions to disk and then execute on your data. When the program is restarted, I will execute those transactions in the exact same order on your data. Provided all such changes are deterministic, we will end up with the exact same state just before the program terminated last time.
This is simply a brilliant idea to persist POJOs. Actually, this is the exact same sequence databases store and re-execute transaction logs after a crash recovery.
Postvayler
However, the thing is Prevayler is a bit too verbose. You need to write Transaction classes for each operation that modifies your data. And it’s also a bit old fashioned considering today’s wonderful @Annotated Java world.
Here comes into scene Postvayler. It’s the predecessor of Chainvayler, which was also a PoC project by myself for transparent POJO persistence.
Postvayler injects bytecode into (instruments) javac compiled @Chained classes such that every @Modification method in a @Chained class is modified to execute that method via Prevayler.
For example, the addBook(Book) method in the introduction sample becomes something like (omitting some details for readability):
void addBook(Book book) {
if (! there is Postvayler context) {
// no persistence, just proceed to original method
__postvayler_addBook(book);
return;
}
if (weAreInATransaction) {
// we are already encapsulated in a transaction, just proceed to original method
__postvayler_addBook(book);
return;
}
weAreInATransaction = true;
try {
prevayler.execute(new aTransactionDescribingThisMethodCall());
} finally {
weAreInATransaction = false;
}
}
// original addBook method is renamed to this
private void __postvayler_addBook(Book book) {
// the contents of the original addBook method
}
As can been seen, if there is no Postvayler context around, the object behaves like the original POJO with an ignorable overhead.
Constructors of @Chained classes are also instrumented to keep track of of them. They are pooled weekly so GC works as expected
Chainvayler
Chainvayler takes the idea of Postvayler one step forward and replicates transactions among JVMs and executes them with the exact same order. So we end up with transparently replicated and persisted POJOs.
Before a transaction is committed locally, a global transaction ID is retrieved via Hazelcast’s
IAtomicLong data structure, which is basically a distributed version of Java’s AtomicLong. Local JVM waits until all transactions up to retrieved transaction ID is committed and then commits its own transaction.
Hazelcast’s IAtomicLong uses Raft consensus algorithm behind the scenes and is CP (consistent and partition tolerant) in regard to CAP theorem and so is Chainvayler.
Chainvayler uses Hazelcast’s IMap data structure to replicate transactions among JVM’s. Possibly, this can be replaced with some other mechanism, for example with Redis pub/sub, should be benchmarked to see which one performs better.
Chainvayler also makes use of some ugly hacks to integrate with Prevayler. In particular, it uses reflection to access Prevayler internals as Prevayler was never meant to be extended this way. Obviously, this is not optimal, but please just remember this is just a PoC project ;) Possibly the way to go here is, enhancing Prevayler code base to allow this kind of extension.
Note, even if persistence is disabled, still Prevayler transactions are used behind the scenes. Only difference is, Prevayler is configured not to save transactions to disk.
Constructors
Possibly, instrumentation of constructors are the most complicated part of Chainvayler and also Postvayler. So best to mention a bit.
First, as mentioned before, except the root object of the chained object graph, creating instances of chained classes are done in regular ways, either with the new operator, or via factories, builders or any other mechanism.
For example, here is a couple of code fragments from the Bank sample to create objects:
Bank other = new Bank();
Customer customer = new Customer(<name>);
Customer customer = bank.createCustomer(<name>);
They look quite the POJO way, right?
Actually many things are happening behind the scenes due to constructor instrumentation:
- First, if there is no Chainvayler context around, they act like a plain POJO. They do nothing special
- Otherwise, the created object gets a unique long id, which is guaranteed to be the same among all JVMs and the object is put to the local object pool with that id
- If necessary, a ConstructorTransaction is created and committed with the arguments passed to constructor.
A ConstructorTransaction is necessary only if:
- We are not already in a transaction (inside a
@Modificationmethod call or in another ConstructorTransaction)
- We are not already in a transaction (inside a
- If this is the local JVM, the JVM which created the object for the first time, it just gets back the reference of the object. All the rest works as plain POJO world.
- Otherwise, if this is due to a remote transaction (coming from another JVM) or a recovery transaction (JVM stopped/crashed and replaying transactions from disk)
- Object is created using the exact same constructor arguments and gets the exact same id
- Object is put to local object pool with that id
- After this point, local and remote JVMs works the same way. Transactions representing
@Modificationmethod calls internally use target object ids. So, as each chained object gets the same id across all JVM sessions,@Modificationmethod calls execute on the very same object.
Constructor instrumentation also does some things which is not possible via plain Java code. In particular it:
- Injects some bytecode which is executed before calling
super class'constructor - Wraps
super class'constructor call in atry/catch/finallyclause.
These are required to handle exceptions thrown from constructors (edge cases) and initiate a ConstructorTransaction in the correct point.
Annotations
@Chained
Marks a class as Chained. @Chained is inherited so subclasses of a chained class are also chained. But it’s a good practice to annotate them too.
Starting from the root class, Chainvayler compiler
recursively scans packages and references to other classes and instruments all the classes marked with the @Chained annotation.
@Modification
Marks a method as Modification. All methods in a @Chained class which modify the data should be marked with this annotation and all such methods should be deterministic.
Chainvayler records invocations to such methods with arguments and executes them in the exact same order on other peers and also when the system is restarted. The invocations are synchronized on the chained root.
@Synch
Marks a method to be synchronized with @Modification methods. Just like @Modification methods, @Synch methods are also synchronized on persistence root.
It’s not allowed to call directly or indirectly a @Modification method inside a @Synch method and will result in a ModificationInSynchException.
@Include
Includes a class and its package to be scanned. Can be used in any @Chained class. This is typically required when some classes cannot be reached by class and package scanning.
SecretCustomer in the bank sample demonstrates this feature.
Consistency
Each Chainvayler instance is strongly consistent locally. That is, once the invocation of a @Modification method completed, all reads in the same JVM session reflect the modification.
The overall system is eventually consistent for reads. That is, once the invocation of a @Modification method completed in one JVM, reads on other JVMs may not reflect the modification.
However, the overall system is strongly consistent for writes. That is, once the invocation of a @Modification method completed in one JVM, writes on other JVMs reflect the modification, @Modification methods will wait until all other writes from other JVMs are committed locally. So they can be sure they are modifying latest version of the data.
In other words, provided all changes are deterministic, any @Modification method invocation on any JVM is guaranteed to be executed on the exact same data.
Performance and Scalability
As all objects are always in memory, assuming proper synchronization, reads should be lightning fast. Nothing can beat the performance of reading an object from memory. In most cases you can expect read times < 1 milliseconds even for very complex data structures. With todays modern hardware, iterating over a Map with one million entries barely takes a few milliseconds. Compare that to full table scan over un-indexed columns in relational databases ;)
Furthermore, reads are almost linearly scalable. Add more nodes to your cluster and your lightning fast reads will scale-out.
However, as it’s now, writes are not scalable. The overall write performance of the system decreases as more nodes are added. But hopefully/possibly there is room for improvement here.
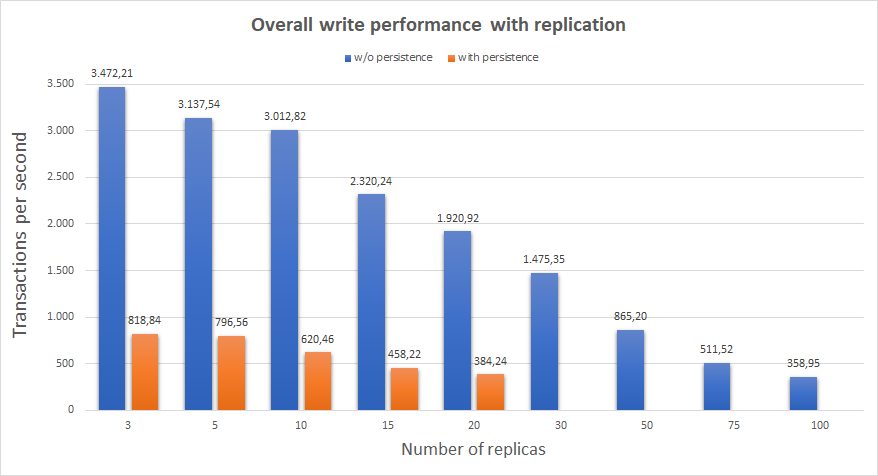
Below chart shows the overall write performance with respect to number replicas. Tested on an AWS EKS cluster with 4 d2.xlarge nodes.
And this one shows local (no replication) write performance with respect to number of writer threads. Tested on an AWS d2.xlarge VM (without Kubernetes)
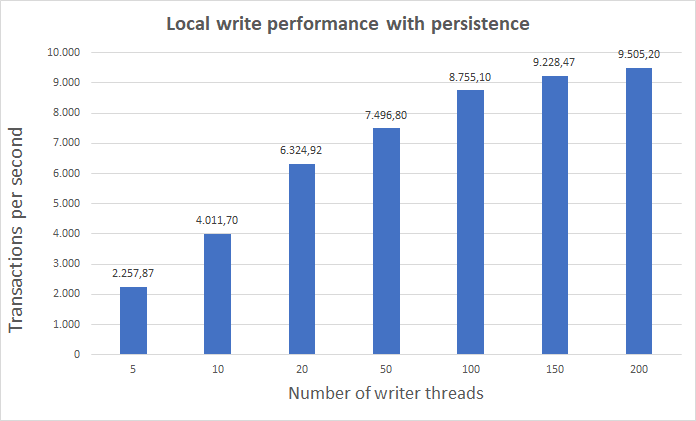
Above chart also suggests, disk write speed is not the bottleneck of low TX/second numbers when both replication and persistence is enabled. Possibly there is a lot to improve here by making disk writes asynchronous.
Note, for some reason I couldn’t figure out yet, Java IO performance drops to ridiculous numbers in Kubernetes after some heavy writes. That’s the reason why high replica counts with persistence are missing in the overall write performance chart and non-replication tests are done on a plain VM.
Determinism
As mentioned, all methods which modify the data in the chained classes should be deterministic. That is, given the same inputs, they should modify the data in the exact same way.
The term deterministic has interesting implications in Java. For example, iteration order of HashSet and HashMap is not deterministic. They depend on the hash values which may not be the same in different JVM sessions. So, if iteration order is significant, for example finding the first object in a HashSet which satisfies certain conditions and operate on that, instead LinkedHashSet and LinkedHashMap should be used which provide predictable iteration order.
In contrast, random operations are deterministic as long as you use the same seed.
Another source of indeterminism is depending on the data provided by external actors, for example sensor data or stock market data. For these kind of situations, relevant @Modification methods should accept the data as method arguments. For example, below sample is completely safe:
@Chained
class SensorRecords {
List<Record> records = new ArrayList<>();
void record() {
Record record = readRecordFromSomeSensor();
record(record);
}
@Modification
void record(Record record) {
records.add(record);
}
}
Note, clock is also an external actor to the system. Since it’s so commonly used, Chainvayler provides a
Clock
facility which can safely be used in @Modification methods instead of System.currentTimeMillis() or new Date().
Clock pauses during the course of transactions and always has the same value for the same transaction regardless of which
JVM session it’s running on.
Audits in the Bank sample demonstrates usage of clock facility.
Clock facility can also be used for deterministic randomness. For example:
@Modification
void doSomethingRandom() {
Random random = new Random(Clock.nowMillis());
// do something with the random value
// it will have the exact same sequence on all JVM sessions
}
Limitations
Memory
Prevayler and hence Chainvayler is limited by memory. As all of the objects are in memory they should fit into memory. As memory is getting cheaper and cheaper everyday, this is not an actual limitation for most of the applications. But of course, Chainvayler is not suitable for applications with a high data grow rate.
Garbage collection
When replication is not enabled, garbage collection works as expected. Any chained object created but not accessible from the root object will be garbage collected soon if there are no other references to it. This is achieved by holding references to chained objects via weak references.
However, this is not possible when replication is enabled. Imagine a chained object is created on a JVM and it’s not accessible from the root object, there are only some other local references to it. Those other local references will prevent it to be garbage collected.
When this chained object is replicated to other JVMs, there won’t be any local references to it, and hence nothing will stop it to be garbage collected if it’s not accessible from the root object.
So, unfortunately, looks like, we need to keep a reference to all created chained objects in replication mode and prevent them to be garbage collected.
Maybe, one possible solution is, injecting some finalizer code to chained objects and notify other JVMs when the chained object is garbage collected in the JVM where the chained object is initially created.
Clean shutdown
When replication is enabled, clean shutdown is very important. In particular, if a node reserves a transaction ID in the network and dies before sending the transaction to the network, the whole network will hang, they will wait indefinitely to receive that missing transaction.
The Bank sample registers a shutdown hook to the JVM and shutdowns Chainvayler when JVM shutdown is initiated. This works fine for demonstration purposes unless JVM is killed with -9 (-SIGKILL) switch or a power outage happens.
But obviously this is not a bullet proof solution. A possible general solution is, if an awaited transaction is not received after some time, assume sending peer died and send the network a NoOp transaction with that ID, so the rest of the network can continue operating.
Comparision to
ORM frameworks
ORM (Object-Relational Mapping) frameworks improved a lot in the last 10 years and made it much easier to map object graphs to relational databases.
However, the still remaining fact is, objects graphs don’t naturally fit into relational databases. You need to sacrifice something and there is the overhead for sure.
I would call the data model classes used in conjunction with ORM frameworks as object oriented-ish, since they are not truly object oriented. The very main aspects of object oriented designs, inheritance and polymorphism, and even encapsulation is either impossible or is a real pain with ORM frameworks.
And they are also not transparent.
Hazelcast
Hazelcast is a great framework which provides many distributed data structures, locks/maps/queues etc. But still, those structures are not drop-in replacements for Java locks/maps/queues, one needs to be aware of he/she is working with a distributed object and know the limitations. And you are limited to data structures Hazelcast provides.
With Chainvayler there is almost no limit for what data structures can be used. It’s truly object oriented and almost completely transparent.
Conclusion
Apparently this library is only a PoC and not production ready yet. However, it works and demonstrates transparent replication and/or persistence is possible.
Once it’s production ready, it can be used in different domains with several benefits:
- Much simpler and natural object oriented code
- Eliminate databases, persistence layers and all the relevant limitations
- Lightning fast read performance
- Any type of Java application which needs to persist data
- If writes can be scaled-out, at least to some level, Chainvayler is a very good fit for microservices applications
- Even not, it can still be a good fit for many microservices applications if they are read-centric
Thanks for making it this far. Happy transparent persistence and replication to your POJOs!